A complete guide to the Page Object Model for Selenium Webdriver

What is the Page Object Model?
The Page Object Model for Selenium, or the POM, is a test design approach that advocates the capturing, defining and storing of web application UI elements that we wish our tests to interact with, in a manner that corresponds very closely to the actual layout or flow of the application under test.
Let's use the Amazon Ecommerce website as a real world example. In any typical Ecommerce web application, I will find many types of application "pages". Commonly found are Product Detail pages, Category Landing Pages, Returned Search Results Listings, User Profile pages, Static Customer help pages etc.
My planned test automation coverage will likely need to cover all of these page types of course and on each page, there will be an assortment of text fields, checkboxes, radio buttons, buttons, page headings and subheadings, drop down lists, text elements, images, banners and many more that I will action or check in some way within any tests.
If I am writing a new automated test for the Product Details page of my Ecommerce web application, Selenium's Page Object Model tells me that I should capture the UI elements that I will need, in a dedicated matching Product Details page within my test automation code. When I then start to capture new UI elements for a test against the Product Listing page, I will need to create a separate page (or object repository) within my test automation project.
The POM tells me that these application page based files are also where I will then write my test methods that make use of the elements that I have just defined within that page.
For example, the web application under test has a Customer Profile page and consequently, my automation project does as well. Not only will I define my UI elements here, but I will also write a method, for example, that allows me to "Change Default Customer Billing Address". So the methods or sequences of user actions required to test a certain function, are written in the same file as the UI elements that they will need to make use of to drive that test.
There is one additional point to make at this stage. Despite being named the "Page Object Model", the approach described above can and should be implemented for anything that may not be a page in its own right, but is still a significant piece of application functionality to test, with multiple elements and a number of methods that would need to be written in order to test it. One such example would typically be the Main Navigation Header for the website. It sits across most pages and is not a page in itself, but it makes absolute sense that the elements and methods that will be written to test it, should be declared in a dedicated "page" file.
Why should I use the Page Object Model for my test automation?
The primary reasons for applying the Page Object Model to your test automation code are to ensure lowest possible ongoing code maintenance via adherence to the D-R-Y (Don't Repeat Yourself) development principle.
What does this really mean in terms of an automated test on an Ecommerce website?
Well, when our previously defined UI elements (drop down list, text field etc.) on a particular page on the site change (and they will!) because of a recently introduced front end bug or planned feature change - when we use the POM, we only have a single place to update our element definition for that specific UI component in our own automation project.
As you will see below when we talk about implementation, if I always refer to a certain element as "country_list_selector" in one or many methods used by many tests in an ever growing regression pack - when the identifier (DOM attribute) for "country_list_selector" changes from 'ABC' to 'DEF' for example, I only need to make that update in one place in my page class (object repository) for all of my tests to continue to run successfully.
If, on the other hand, I have not used the POM and I have 100 tests, collectively calling 15 methods, that each refer to that drop down list as 'ABC' and not an alias like "country_list_selector" - well, I then need to make that update from 'ABC' to 'DEF' in 15 different places before those 100 tests will run smoothly.
This is what we mean when we say Don’t-Repeat-Yourself and keep your code maintenance low. I only need to update my single element identifier (alias) when necessary and not my tests. My tests are written to always use an alias for each element and I enjoy the advantage of clear separation between page elements and test code.
How can I implement the Page Object Model?
So let’s take the theory of the Page Object Model that we’ve just outlined and now apply that to a real world Ecommerce automated test written in Ruby (with Watir) where we visit the homepage, search for a product, curate the returned results, add a product to cart, sign in and begin the checkout flow and eventually abandon and empty the cart to reset the test.

In the image above, we start with a dedicated Page file/class that represents just our Homepage within the application under test.
This Homepage page class contains a single test flow method - “search for product”.
It also contains the UI element definitions for just 2 elements, most commonly associated with that page - the “accept cookies” button and the product “search bar”.
The method itself will click the “accept cookies” button if it finds it. It will then submit and enter a search string within the “search box” text entry field.
And let’s consider our 2 element definitions.

The “accept cookies” button has been defined by the tester as: element(:accept_cookies) { input id: 'sp-cc-accept' }
The “search box” text entry field has been defined as: element(:search_box) { div(class: 'nav-search-field').text_field }
Focusing on just the “search box”, the tester in this case has made use of a 2 part element definition. Firstly, they have ascertained that it can be easily identified as a DIV, with the use of the CLASS attribute which in this case is 'nav-search-field'. Finally, to be specific as to the type of UI element we are trying to target, the tester has added a second part to the element definition, as a child of the DIV, referring to it simply as text_field.
We’ll now follow this breakdown throughout the remaining application page classes.

A dedicated Search Results page class containing 3 methods, making use of 4 defined elements.
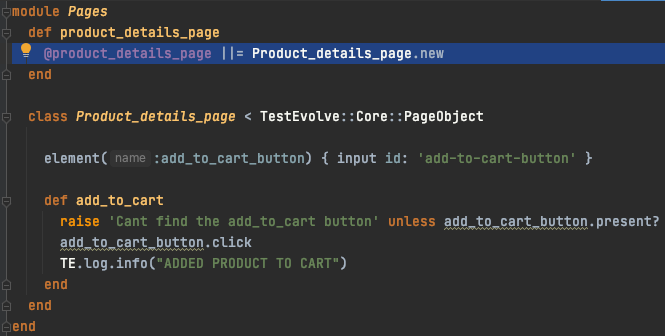
A dedicated Product Details Page page class containing a single method and a single element.

A dedicated Login Page page class containing a single method and making use of 8 defined elements.

And finally, a dedicated Shopping Cart page class containing a single method employing 2 unique elements.
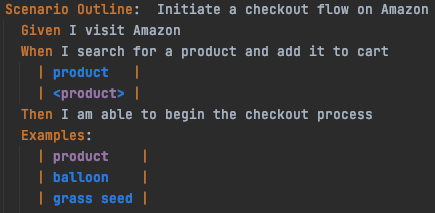
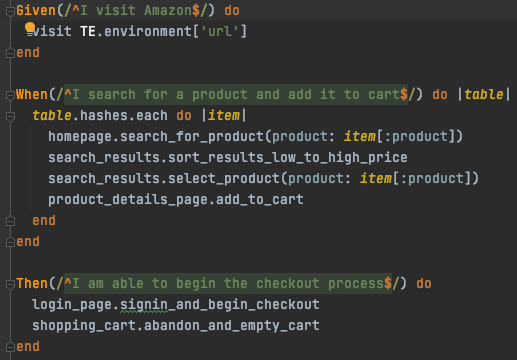
In the two images below, when we pull it all together with a Cucumber Feature/Scenario and its supporting Step Definition file, we can see in effect what resembles a very easy to read test script, that clearly documents the flow of the test with reference to the application matching page classes and a descriptive method or user action.
In Summary - why the Page Object Model is a great test automation design pattern to use
We can reduce code maintenance and separate tests from UI elements in our code.
We can employ a logical application-matching page structure to our automation projects.
We can use a clean simple element naming convention for our application components that we need to interact with.
When the front end changes, we enjoy the quickest and simplest approach to refactor our code as necessary, with a single page and single element to update in any circumstance.
We highly recommend that you employ the POM within your selenium test automation projects.
Page Object Model FAQs
-
The Page Object Model or POM advocates that you have pages or classes in your automation code that very closely resemble the pages or large areas of functionality in your application under test. UI elements in your application that are required by your automated tests are saved, once only, in the relevant page class in your automation project.
-
The Page Object Model helps to keep your code clean, concise and easily maintainable. Changing UI elements only need to be updated in a single place.
-
The Page Object Model originates from and was popularised by the Selenium Webdriver community.
-
The fundamental risk of not using a Page Object Model is ending up with an unmaintainable, messy, automation codebase that will quickly become obsolete as UI based tests start to fail and the cost of fixing them outweighs the benefit of their existence in the first place.


James is a software testing professional at Test Evolve with extensive experience in agile testing, test automation, and quality engineering. He shares practical insights from real-world projects to help teams improve test coverage, accelerate releases, and adopt smarter testing practices that support continuous delivery and long-term product quality.

Mark Sweetlove is a seasoned software tester and front-end developer with over 15 years of hands-on experience in the IT industry. At Test Evolve, he plays a pivotal role in developing and testing the Flare and Spark products, combining deep technical knowledge with a practical understanding of modern software delivery. Mark specializes in Ruby, JavaScript, and TypeScript, and applies this expertise to create scalable, maintainable systems that support continuous delivery and high product quality. His dual perspective as both a developer and tester gives him a unique edge in solving complex quality engineering challenges.